FusionInsight Big Data Platform
FusionInsight provides a comprehensive Big Data software platform for batch and real-time analytics using open-source Hadoop and Spark technologies.
The system leverages HDFS, HBase, MapReduce, and YARN/Zookeeper for Hadoop clustering, along with Apache Spark for faster real-time analytics and interactive queries. Solr adds powerful full-text searching of rich text documents (Word and PDF files), and rich APIs and development tools let you customize the system for specialized data analysis.
Extract big value from Big Data faster and easier with Huawei’s enterprise-class FusionInsight data analysis platform.
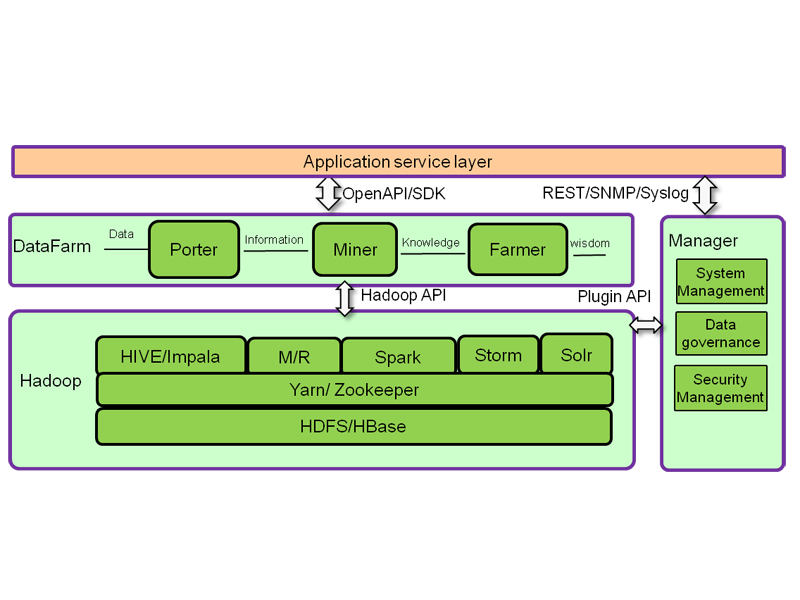
FusionInsight brings Big Data Hadoop and Spark technologies together in an integrated, enterprise-class software platform for faster data analysis and better decision-making
- Optimized for agility: Comprehensive, fully featured Big Data analytics platform with open architecture and APIs supporting batch processing, micro-batch processing, and real-time processing for flexible analysis and integration with enterprise data processing
- Smart: Over one million dimensions in data modeling enable deep insights into user behaviors, helping enterprises to quickly make decisions and respond to market and business opportunities
- Trustworthy: Reliable, high-performance data processing with the reliability, stability, and security expected in enterprise-class applications and mission-critical financial systems
Performance Specifications
| Component | Processing Metrics and Response Times | System Environment |
| Parallel Computing Engine (MapReduce) |
|
Cluster scale: 12 nodes
Typical node configuration: |
| Parallel Computing Engine (Spark) |
|
|
| Hive |
|
|
| HBase |
|
Algunas de nuestras REPRESENTACIONES



